Data Mining 3D Protein Structures, CyVerse Style
CyVerse community member Peter Rose and his team have developed a structural bioinformatics application that provides reproducibility, scalability, and interactivity to efforts to mine the worldwide Protein Data Bank.
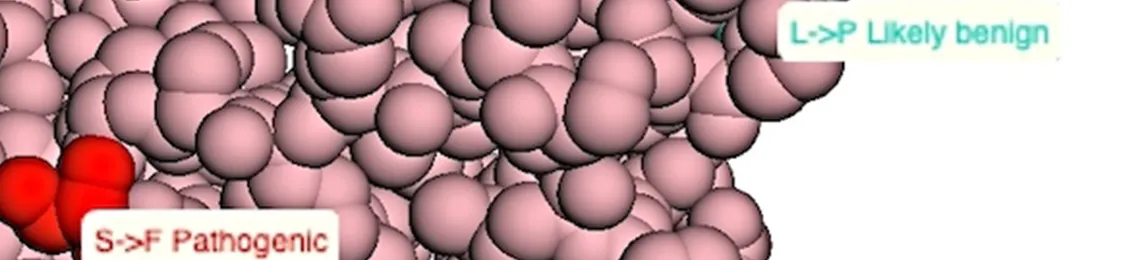
Mapping missense mutations from dbSNP to 3D structures – just one of numerous options for data mining the worldwide Protein Data Bank. Image courtesy of: https://github.com/sbl-sdsc/mmtf-genomics
The application is available through CyVerse’s Visual and Interactive Computing Environment (VICE) in the CyVerse Discovery Environment.
“We want to create a research analysis environment that’s scalable, reproducible, and able to run in minutes so you don’t have to start the analysis and come back the next day,” said Peter Rose, who directs the Structural Bioinformatics Laboratory at the San Diego Supercomputer Center (SDSC) at the University of California, San Diego.
Rose’s lab’s main focus is developing analytical tools such as MMTF pyspark to mine the Protein Data Bank (PDB), which is the only worldwide archive of experimentally-determined structures of proteins, nucleic acids, and complex assemblies. The PDB is a vital resource for bio-scientists and educators alike.
When Rose introduced his software tools in Jupyter Notebooks during the Structural Bioinformatics Training Workshop and Hackathon at SDSC in 2018, the platform was highly popular. Project Jupyter consists of open-source software, standards, and services, and its Notebook and Lab web applications enable users to create and share live code documents, equations, visualizations, and narrative text.
Rose looked into hosting his software applications in major public and academic clouds, but for most, this meant setting up the entire infrastructure, including Jupyter Hub and user accounts, which would have been time and resource consuming for his team. “Then, Rose said, “I heard about CyVerse.”
The VICE platform, developed by CyVerse, allows users to launch web-based applications in the CyVerse Discovery Environment and interactively respond to preliminary results. Once an application is launched, users can access the VICE app through a linked URL and bring their data from the CyVerse Data Store into the application, or pull data from anywhere on the web using standard requests. VICE also allows researchers to access commonly used Integrated Development Environments (analytical services such as Jupyter Notebooks) and interact with the complex computational processes during their analyses through easy-to-use graphic user interfaces.
Before he found VICE, Rose had been struggling to use a public resource called Binder to host Jupyter Notebooks, trying to overcome limitations such as lack of adequate compute power and memory, no user accounts, and no ability to store data and results.
“All of that is solved by CyVerse,” he said. “First, you can get a larger virtual machine with lots of memory; that addresses our scalability objective. Second, CyVerse uses Docker images, which contain an entire software environment and thus allow us to address reproducibility – we need only cite the image used and it’s there for another researcher to replicate the analysis without the need to worry about installing all the software. The third part, especially with VICE, is the interactivity. VICE enables interactive data-driven discovery at scale.”
“CyVerse will be the major infrastructure to host our applications,” Rose continued, “and we will take advantage of the Data Store and Data Commons because we need to share datasets publicly. CyVerse is a great environment not just for hosting software applications, but also for the associated data.”
“MMTF pyspark from Rose’s group is an exemplar project that extends contemporary open source ‘big data’ platforms and tools such as Apache Spark and Parquet, and complements them with novel data compression and visualization methods developed in their lab,” said Nirav Merchant, CyVerse Co-Principal Investigator at the University of Arizona (UA). “They have created a unique, user friendly, versatile, and highly scalable analysis system that enables users to perform analyses without having to deal with the underlying complex technology stack that allows MMTF pyspark to rapidly process and visualize large amounts of data.”
“Integrating applications like MMTF pyspark with researchers’ own data and democratizing access to it is central to CyVerse’s mission,” said CyVerse Principal Investigator Parker Antin. “MMTF pyspark speaks volumes for the creativity and ingenuity of Rose’s team and their ability to leverage and integrate multiple complex pieces of technologies. We are delighted that MMTF pyspark is able to make use of distinct components in our cyberinfrastructure and support the research and innovation needs for their user community.”
Rose will demonstrate his application during a live CyVerse Focus Forum webinar on March 22 entitled “Deploying Interactive, Scalable Structural Bioinformatics Analyses via VICE.” Learn more and register here.
“I’ll show how CyVerse addresses the issues of scalability, reproducibility, and interactivity,” Rose said. “I’ll go through how to set up a tool, how to set up an app, how to take the software that you have and make it accessible through CyVerse VICE, and then give an introduction to our specific project and a demo of a prototype application, mmtf-genomics, for visualizing mutations mapped to 3D protein structures – which of course is the most exciting thing to see.”
Rose’s current work is supported by the National Cancer Institute of the National Institutes of Health under Award Number U01CA198942. CyVerse is funded by the National Science Foundation.